软件工程个人项目–数独
项目相关连接
Github项目地址:https://github.com/Garvey98/Sudoku
项目博客地址: https://garvey98.github.io/2018/12/02/Sudoku/
项目使用方法见github对应链接中的的README.md文档
PSP表格
| PSP 2.1 | Personal Software Progress Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 30 |
| Estimate | 估计这个计划需要多少时间 | 7000 | 5250 |
| Development | 开发 | 3000 | 2500 |
| Analysis | 需求分析(包括学习新技术) | 2000 | 1200 |
| Design Spec | 生成设计文档 | 120 | 60 |
| Design Review | 设计复审(和同事审核设计文档) | 90 | 60 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 90 | 60 |
| Design | 具体设计 | 300 | 300 |
| Coding | 具体编码 | 600 | 800 |
| Code Review | 代码复审 | 60 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 40 |
| Reporting | 报告 | 60 | 90 |
| Test Report | 测试报告 | 60 | 40 |
| Size Measurement | 计算工作量 | 20 | 10 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 60 | 30 |
| 合计 | 6820 | 5250 |
解题思路
项目简介
实现一个命令行程序,程序能实现两个要求:
- 生成不重复的数独终局至文件
- 读取文件内的数独问题,求解并将结果输出到文件
- GUI实现生成题目,完成数独,提交后判断正确性
具体项目介绍及使用方法见github
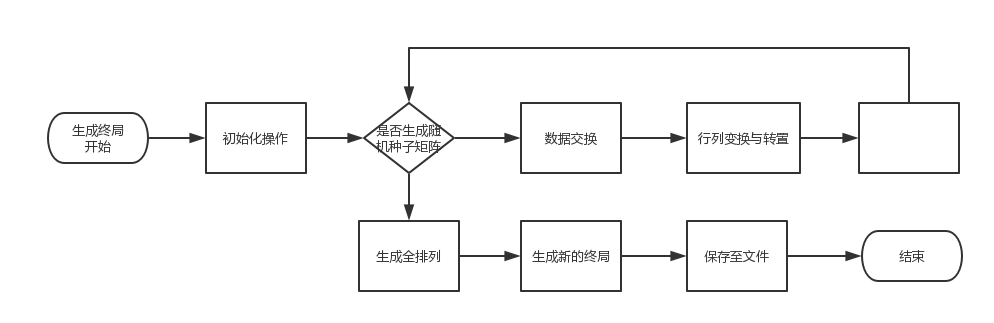
生成终局思路
经过个人的思考和在网上查阅相关算法进行学习,大致有三个思路:
- 暴力深搜 + 回溯
- 矩阵变换
- 全排列
对比这三种算法,第一种是最基础的也是性能最差的,我们不予考虑。
第二种算法的具体操作是有一个初始的数独矩阵,通过进行数据交换,行列交换,转置等变幻出新的矩阵。优点是随机性强,可用于产生前后两个差距很大的数独矩阵,并且很难有重复的,重复的概率很小。缺点是产生的数独终局过多时,耗时较长,且有风险存在重复的数独终局,可能会不满足要求中的不重复。具体内容思路参考终盘生成之矩阵转换法 。
第三种算法是通过全排列快速产生数独,在本项目中,由于左上角数字是固定的,所以对于一个数独,可以通过全排列剩下的八个数字,产生 8!=40320种。全排列的思路可参考一个高效率生成数独的算法 。
在该项目中,我一开始选择的是第二种算法,矩阵变换,但由于性能原因,我开始参考第三种算法全排列,以追求时间上的高效。我通过控制每产生40320个数独,就改变一次种子数独(利用矩阵变换),成功结合了二三种方法的优点,成功实现了最后的高效算法。
求解数独思路
求解数独的算法也有很多,在经过个人思考和参考了网上的一些资料后,发现基本思路大致有两种:
- 深搜 + 剪枝
- Dancing Links
本项目中,我采用的是深搜和回溯来实现,即使是这种思路,但不同的剪枝回溯思路会导致算法性能的极大不同。刚开始的思路就是从左到右,从上到下对于每一个未填入的数字,遍历1-9,进行深搜,直到出现数独约束矛盾,回溯剪枝。后来发现,这种算法有大量重复运算。于是决定,在进行数独约束检查时,每次都要检查该行、该列、该块。于是就选择控制对数字填入的可能性,先遍历数独矩阵检查行、列、块约束,得出每一行、每一列、每一块所决定的未填入数字位置的可能情况,大大减少了约束检查时间。后来经过参考网上思路,发现可以先检查可能值最小的位置,可以减少错误的搜索时间,即变量顺序的抉择,从而得到了最终的回溯搜索算法。
参考资料:
设计实现过程
代码组织
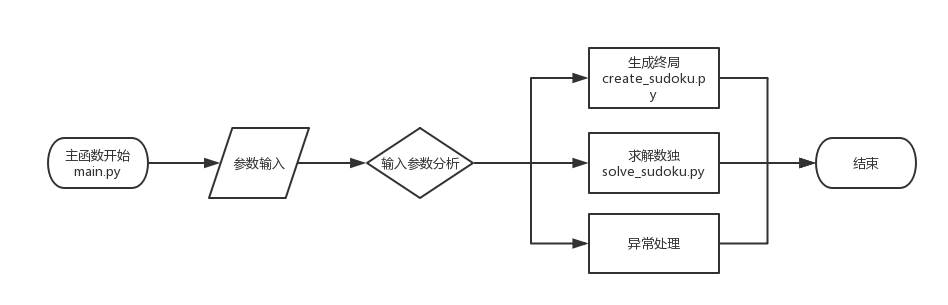
项目代码主要包含三个文件,相应功能如下:
main.py:程序的入口,用来解决参数输入,异常处理,功能调用与输出。create_sudoku.py:内含类CreateMySudoku,用于实现生成终局。solve_sudoku.py:内含类SolveMySudoku,用于实现求解数独。
class CreateMySudoku:
__init__(self, count):初始化函数,打开输出文件并清空上次内容,保存本次生成结果change_root:改变作为种子的数独矩阵,以便再次利用全排列生成终局num_pos:分析数独矩阵,将相同数字的位置存下change_root(self):选择多个数据进行交换,打乱数独矩阵perm(self):通过全排列产生数独终局rowcolumn_exchange(self):行列交换与转置generate_sudoku(self):控制函数,根据产生终局的数量控制函数调用data_exchange(self, shudu, n_num):按照一定位置,一定数据,对数独矩阵进行更新
class SolveMySudoku:
__init__(self, Soduku_Path):读取指定路径的文件内容,分组解决数独问题,初始化输出答案文件,并将结果写入文件。smallest_possibility_first_dfs(self, blank, row_num, col_num, block_num):最小变量优先的最小值深度优先搜索solve_the_sudoku(self):分析数独题目矩阵,保留所需的信息
流程图
主函数流程图
生成数独终局流程图
求解数独流程图

单元测试用例
python ./main.py -c 100000python ./main.py -s Sudoku_Problem.txtpython ./main.py abc depython ./main.py -s adsf
其中,Sudoku_Problem.txt内的用例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
290 0 9 0 0 8 0 4 0
6 0 0 0 0 0 0 1 7
0 1 0 0 4 0 0 0 0
0 0 0 0 0 0 0 0 4
4 8 0 6 0 3 0 2 1
3 0 0 0 0 0 0 0 0
0 0 0 0 9 0 0 8 0
2 4 0 0 0 0 0 0 6
0 5 0 7 0 0 1 0 0
5 3 0 0 7 0 0 0 0
6 0 0 1 9 5 0 0 0
0 9 8 0 0 0 0 6 0
8 0 0 0 6 0 0 0 3
4 0 0 8 0 3 0 0 1
7 0 0 0 2 0 0 0 6
0 6 0 0 0 0 2 8 0
0 0 0 4 1 9 0 0 5
0 0 0 0 8 0 0 7 9
8 0 0 0 0 0 0 0 0
0 0 3 6 0 0 0 0 0
0 7 0 0 9 0 2 0 0
0 5 0 0 0 7 0 0 0
0 0 0 0 4 5 7 0 0
0 0 0 1 0 0 0 3 0
0 0 1 0 0 0 0 6 8
0 0 8 5 0 0 0 1 0
0 9 0 0 0 0 4 0 0
质量分析
我使用了Codacy实时在线代码质量分析工具,对项目进行了质量分析报告,并消除了所有警告,得到A级评价。但是在代码质量分析时,由于时间问题,我们没有对GUI的部分进行测试,所以GUI很丑哦,欲看请三思哦
性能分析
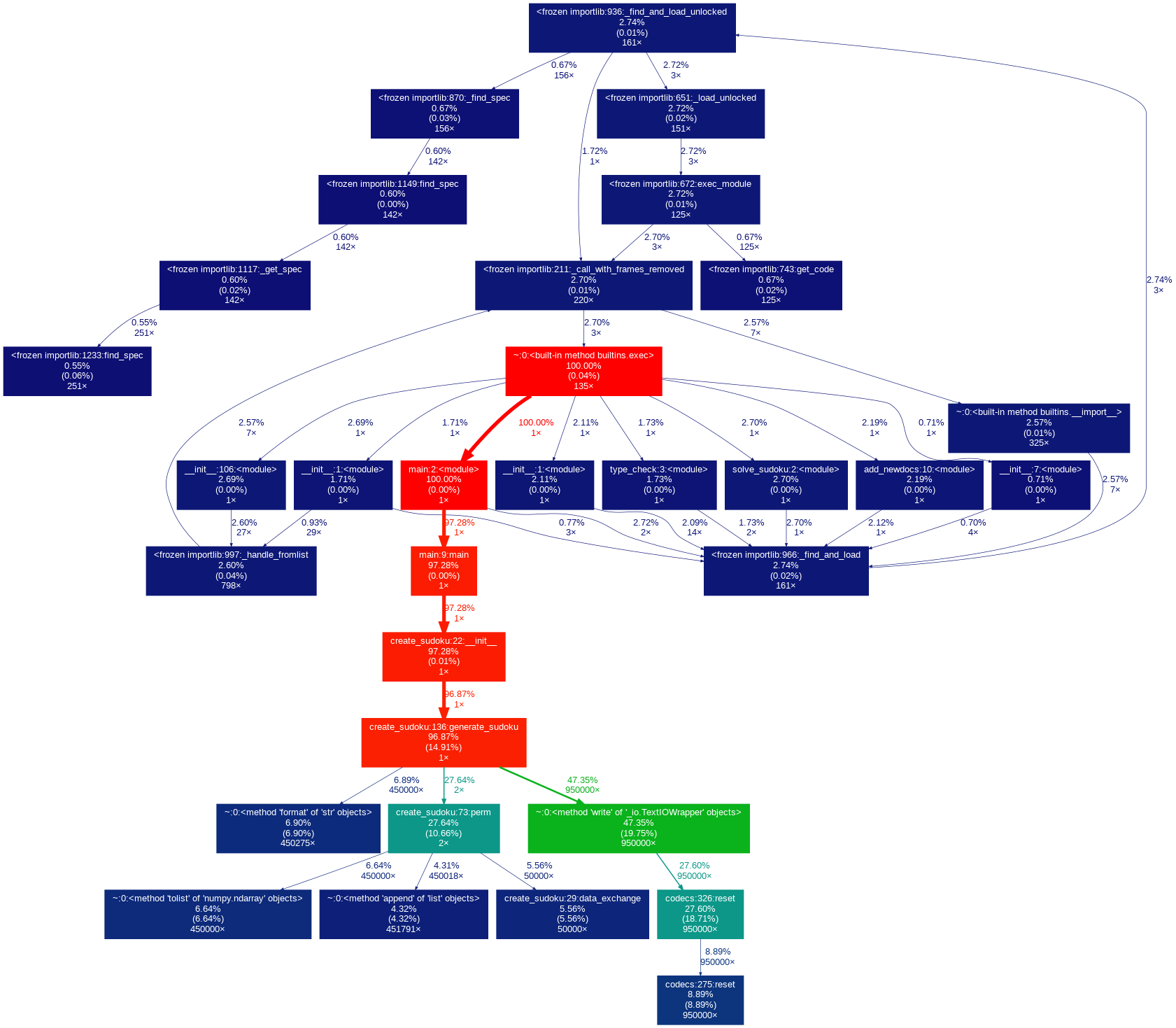
生成终局性能分析
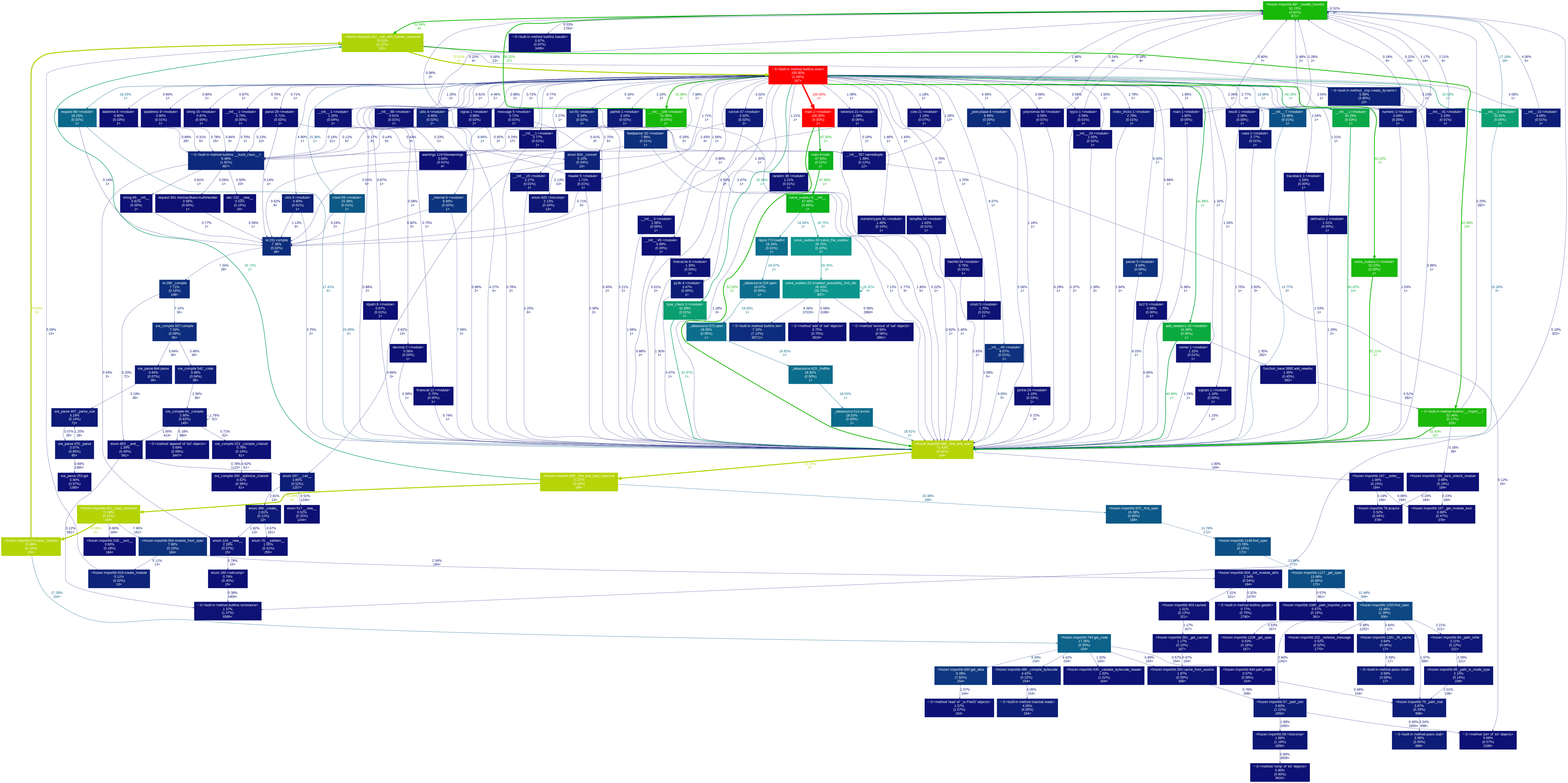
求解数独性能分析
性能改进
生成终局改进思路
刚开始采用的是纯矩阵变换,即随机数据交换,行列变换和转置来生成新的终局。但由于交换次数过多导致大量数据交换,耗时极长。
后来经过学习,决定采用全排列的方式快速生成终局,虽然保障了1000个矩阵不重复,但对于每次全排列,只能产生8!个新终局。
最后决定采用矩阵变换生成种子矩阵,每个种子矩阵产生后即可通过全排列生成新的矩阵。即节省了时间,也保障了可生成大量不重复的终局。
另一个重要问题是文件输出速度的改进,原来是产生一个新数独终局输出一次,后来改为将所有数独拼接成一个大的list,再按照格式一次输出完。
求解数独改进思路
刚开始的思路就是从左到右,从上到下对于每一个未填入的数字,遍历1-9,进行深搜,直到出现数独约束矛盾,回溯剪枝。后来发现,这种算法有大量重复运算。于是决定,在进行数独约束检查时,每次都要检查该行、该列、该块。于是就选择控制对数字填入的可能性,先遍历数独矩阵检查行、列、块约束,得出每一行、每一列、每一块所决定的未填入数字位置的可能情况,大大减少了约束检查时间。后来经过参考网上思路,发现可以先检查可能值最小的位置,可以减少错误的搜索时间,即变量顺序的抉择,从而得到了最终的回溯搜索算法。
代码说明
create_sudoku.py
先描述create_sudoku.py的代码细节,主体部分是一个类CreateMySudoku,用于实现初始化,生成种子矩阵(行列变换与转置),分析数独矩阵,全排列,控制生成特定数目的数独终局1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152#!/usr/bin/python3
""" This is the module that generates the sudoku endings"""
import random
import numpy as np
class CreateMySudoku():
""" This is the class that generates the sudoku endings"""
root_shudu = np.array([[1, 9, 6, 4, 3, 8, 7, 5, 2],
[3, 8, 4, 5, 7, 2, 1, 6, 9],
[7, 2, 5, 6, 1, 9, 3, 4, 8],
[5, 7, 2, 1, 6, 3, 9, 8, 4],
[6, 3, 1, 8, 9, 4, 5, 2, 7],
[9, 4, 8, 2, 5, 7, 6, 1, 3],
[2, 5, 7, 9, 4, 1, 8, 3, 6],
[4, 1, 9, 3, 8, 6, 2, 7, 5],
[8, 6, 3, 7, 2, 5, 4, 9, 1]])
count_need = 0
s = []
num_position = []
def __init__(self, count):
""" Initializes the generated file and calls the generation function """
with open('sudoku.txt', 'a+') as sudoku_file:
sudoku_file.truncate(0)
self.count_need = count
self.generate_sudoku()
def data_exchange(self, shudu, n_num):
""" Data transformation"""
for i in range(8):
for (row, col) in self.num_position[i]:
if shudu[row][col] == n_num[i]:
break
shudu[row][col] = n_num[i]
return shudu
def change_root(self):
""" Change sudoku map"""
numofexchange = 1
temp_list = [2, 3, 4, 5, 6, 7, 8, 9]
while numofexchange < 5:
random.shuffle(temp_list)
random_num = temp_list[1]
if random_num == 9:
for i in range(9):
for j in range(9):
if self.root_shudu[i][j] == random_num:
self.root_shudu[i][j] = 2
elif self.root_shudu[i][j] == 2:
self.root_shudu[i][j] = 9
else:
for i in range(9):
for j in range(9):
if self.root_shudu[i][j] == random_num:
self.root_shudu[i][j] = random_num+1
elif self.root_shudu[i][j] == random_num+1:
self.root_shudu[i][j] = random_num
numofexchange += 1
return self.root_shudu
def num_pos(self):
""" Find the same number position"""
self.num_position = []
for i in range(8):
self.num_position.append(set())
for i in range(9):
for j in range(9):
if self.root_shudu[i][j] != 1:
self.num_position[self.root_shudu[i][j]-2].add((i, j))
# return self.num_position
def perm(self):
""" Full Permutation"""
n_num = [2, 3, 4, 5, 6, 7, 8, 9]
tempcount = 40320
tempshudu = []
for row in range(9):
tempshudu.append(self.root_shudu[row])
while tempcount > 0 and self.count_need > 0:
tail = 7
j = 7
tempshudu = self.data_exchange(tempshudu, n_num)
for row in range(9):
self.s.append(tempshudu[row].tolist())
tempcount -= 1
self.count_need -= 1
if tempcount == 0 or self.count_need == 0:
break
while j >= 1:
i = j - 1
if n_num[i] < n_num[j]:
temp_j = tail
k = i + 1
while temp_j > i:
if n_num[temp_j] > n_num[i] and n_num[temp_j] < n_num[k]:
k = temp_j
temp_j -= 1
n_num[i], n_num[k] = n_num[k], n_num[i]
if len(n_num) > j:
i = j
temp_j = tail
while i < temp_j:
n_num[i], n_num[temp_j] = n_num[temp_j], n_num[i]
i += 1
temp_j -= 1
j = tail
tempshudu = self.data_exchange(tempshudu, n_num)
for row in range(9):
self.s.append(tempshudu[row].tolist())
tempcount -= 1
self.count_need -= 1
if tempcount == 0 or self.count_need == 0:
break
else:
j -= 1
return self.count_need
def rowcolumn_exchange(self, change_num):
""" Row and column transformation"""
numofexchange = 1
temp_list = [1, 2, 3, 4, 5, 6, 7, 8]
while numofexchange < change_num:
random.shuffle(temp_list)
rownum = temp_list[1]
if (rownum % 3) == 2:
self.root_shudu[[rownum, rownum-1],
:] = self.root_shudu[[rownum-1, rownum], :]
else:
self.root_shudu[[rownum, rownum+1],
:] = self.root_shudu[[rownum+1, rownum], :]
self.root_shudu = self.root_shudu.T
numofexchange += 1
return self.root_shudu
def generate_sudoku(self):
""" Generate a certain number of sudoku endings"""
while self.count_need > 0:
self.change_root()
self.rowcolumn_exchange(4)
self.num_pos()
self.count_need = self.perm()
rowcount = 0
with open('sudoku.txt', 'a+') as sudoku_file:
for row in self.s:
rowtxt = '{} {} {} {} {} {} {} {} {}'.format(
row[0], row[1], row[2], row[3], row[4], row[5], row[6], row[7], row[8])
sudoku_file.write(rowtxt)
sudoku_file.write('\n')
rowcount += 1
if rowcount % 9 == 0:
sudoku_file.write('\n')
solve_sudoku.py
solve_sudoku.py的代码细节如下,在初始化之后,先遍历数独矩阵检查行、列、块约束,得出每一行、每一列、每一块所决定的未填入数字位置的可能情况,大大减少了约束检查时间。再先检查可能值最小的位置,可以减少错误的搜索时间,即变量顺序的抉择,从而得到了最终的回溯搜索算法,最小可能位置优先的DFS1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90import numpy as np
class SolveMySudoku():
""" This is the class that solves the sudoku"""
mysudoku = np.zeros((9, 9), dtype=int)
def __init__(self, Soduku_Path):
""" Load the sudoku from the file and call the solution function to output the result"""
allmysudoku = np.loadtxt(Soduku_Path, dtype=int)
sudoku_count = int(len(allmysudoku)/9)
sudoku_now = np.split(allmysudoku, sudoku_count)
with open('Sudoku_Problem_Answer.txt', 'a+') as sudoku_answer:
sudoku_answer.truncate(0)
for mysudoku1 in sudoku_now:
self.mysudoku = mysudoku1
self.solve_the_sudoku()
np.savetxt(sudoku_answer, self.mysudoku, fmt="%d")
sudoku_answer.write('\n')
def smallest_possibility_first_dfs(self, blank, row_num, col_num, block_num):
""" Select the location with the fewest possible values for depth-first search"""
blank_length = len(blank)
if blank_length == 0:
return True
all_num = set(range(1, 10))
smallest_possible_case = 9
for (row, col) in blank:
possibility = all_num - \
(row_num[row] | col_num[col] | block_num[row//3][col//3])
if len(possibility) <= smallest_possible_case:
smallest_possible_case = len(possibility)
i = row
j = col
if smallest_possible_case == 0:
return False
blank.remove((i, j))
possibility = all_num - \
(row_num[i] | col_num[j] | block_num[i//3][j//3])
for num in possibility:
row_num[i].add(num)
col_num[j].add(num)
block_num[i//3][j//3].add(num)
self.mysudoku[i][j] = num
if self.smallest_possibility_first_dfs(blank, row_num, col_num, block_num):
return True
self.mysudoku[i][j] = 0
row_num[i].remove(num)
col_num[j].remove(num)
block_num[i//3][j//3].remove(num)
blank.add((i, j))
return False
def solve_the_sudoku(self):
""" Analyze rows, columns, and blocks of sudoku"""
col_num = []
row_num = []
block_num = [[0]*3 for i in range(3)]
for i in range(9):
col_num.append(set())
row_num.append(set())
for i in range(3):
for j in range(3):
block_num[i][j] = set()
blank = set()
for i in range(9):
for j in range(9):
if self.mysudoku[i][j] != 0:
if self.mysudoku[i][j] not in row_num[i]:
row_num[i].add(self.mysudoku[i][j])
if self.mysudoku[i][j] not in col_num[j]:
col_num[j].add(self.mysudoku[i][j])
if self.mysudoku[i][j] not in block_num[i//3][j//3]:
block_num[i//3][j//3].add(self.mysudoku[i][j])
else:
blank.add((i, j))
self.smallest_possibility_first_dfs(
blank, row_num, col_num, block_num)
main.py
程序的入口,用来解决参数输入,异常处理,功能调用与输出。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39import time
import sys
import solve_sudoku
import create_sudoku
def main():
""" This is function main"""
try:
time_start = time.time()
para = sys.argv[1]
if para == '-c':
sudoku_count = int(sys.argv[2])
if sudoku_count <= 0:
raise ValueError
create_sudoku.CreateMySudoku(sudoku_count)
elif para == '-s':
sodoku_path = sys.argv[2]
solve_sudoku.SolveMySudoku(sodoku_path)
else:
print("Invalid command.")
print("You can type the command 'python main.py' to view valid commands.")
except ValueError:
print("The second argument should be a positive integer.")
except IOError as err:
print("File does not exist.", err)
except IndexError:
print("Need two parameters, here is how to use it:")
print("[Type the command]`python main.py -c 100`: Generate 100 sudoku endings.")
print("[Type the command]`python main.py -s \"Sudoku_Problem.txt\"`: \
Solve the sudoku in \"Sudoku_Problem.txt\".")
finally:
print("Using time: ", time.time()-time_start)
if __name__ == "__main__":
main()
总结收获
在完成这次个人项目的过程中,我深刻认识到一个软件开发的整个过程的艰难,从需求分析到开发的整个步骤,包括后来的代码附身与测试报告,每一步都走的很艰难。尤其是在开发过程中,刚开始由于对需求分析的轻视,以及对开发模型的疏忽,导致后来在开发过程中,遇到了很多问题,这些问题的维护与解决都耗费了我大量的时间与精力,如果在刚开始的模型设计和需求分析中我能够更加仔细一点,就会少走很多弯路。另外一点收获就是我对python的掌握更加熟悉了,学会了很多新的技能,包括代码的质量分析,性能分析,单元测试的设计等,还有最后比较匆忙实现的GUI部分!